![]()
![]()
![]()
![]()
Der Systemeditor edit gehört nicht zu dem Statistikpaket UNIXSTAT, sondern entstammt der Produktpalette von Microsoft. Es handelt sich dabei um einen ASCII-Editor, d.h. die Textdateien werden auch so abgespeichert, wie man sie sieht (bei anderen Editoren, z.B. Word, werden noch zusätzliche Zeichen, z.B. die Formatierungen, gespeichert). edit ist jedoch im Lieferumfang von MS-DOS enthalten und sollte darum auf jedem DOS-Rechner verfügbar sein.
Es soll folgende Tabelle an Werten eingegeben werden (jeweils <Größe> TAB <Gewicht>):
|
Größe [cm] |
Gewicht [kg] |
|
|
1 |
182 |
62 |
|
2 |
165 |
62 |
|
3 |
172 |
60 |
|
4 |
170 |
64 |
|
5 |
193 |
82 |
|
6 |
166 |
51 |
|
7 |
180 |
67 |
|
8 |
163 |
52 |
|
9 |
182 |
59 |
|
10 |
160 |
56 |
|
11 |
164 |
55 |
|
12 |
173 |
62 |
|
13 |
163 |
66 |
|
14 |
176 |
58 |
|
15 |
166 |
63 |
Folgendes ist zu beachten:
stat < foo
Ein Beispiel für den Aufruf ohne Argument (bzw. ohne Datendatei) könnte folgendermaßen aussehen:
stats: Reading input from terminal: 1 2 3 4 5 6 ^Z n = 6 min = 1 max = 6 sum = 21 ss = 91 mean = 3.5 var = 3.5 sd = 1.870829 se = 0.763763 skew = 0 kurt = 1.202381
Der Output ist dabei folgendermaßen zu interpretieren:
![]()
![]()
![]()
![]()
desc funktioniert ähnlich wie stats; der Output ist nur noch etwas genauer (hier exemplarisch :für die selben Werte, die auch beim obigen Beispiel eingegeben wurden):
------------------------------------------------------------
Under Range In Range Over Range Sum
0 6 0 21.000
------------------------------------------------------------
Mean Median Midpoint Geometric Harmonic
3.500 3.500 3.500 2.994 2.449
------------------------------------------------------------
SD Quart Dev Range SE mean
1.871 1.500 5.000 0.764
------------------------------------------------------------
Minimum Quartile 1 Quartile 2 Quartile 3 Maximum
1.000 2.000 3.500 5.000 6.000
------------------------------------------------------------
Skew SD Skew Kurtosis SD Kurt
0.000 1.000 1.202 2.000
------------------------------------------------------------
Null Mean t prob (t) F prob (F)
0.000 4.583 0.006 21.000 0.006
------------------------------------------------------------
Dabei gelten folgende Definitionen:
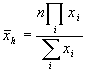
dm (data manipulation) ist ein sehr vielseitiges Programm, das der Manipulation von Datenfiles dient. In dem obigen Beispiel mit Körpergröße und Gewicht kann man die erstellte Datei nicht als sinnvollen Input für stats verwenden, da die entsprechenden deskriptiven Werte über alle enthaltenen Zahlen berechnet werden (und beispielsweise eine Mittelwertsbildung von Körpergröße und Gewicht wenig Sinn macht).
Mit dm kann man z.B. einzelne Spalten aus einer Datei herausziehen. dm verfügt über einen großen Funktionsumfang. Das Argument s1 extrahiert beispielsweise die erste Spalte, s2 die zweite usw. Bitte die entsprechende Man-Page lesen.
Nun können wir unsere Beispieldatei mit Körpergröße und Gewicht z.B. nach der ersten Spalte (Größe) auswerten:
dm < foo.dat | desc
Da gibt es mehrere Möglichkeiten von zunehmender Komplexität:
desc < grgew.dat(der Input, der normalerweise von der Tastatur erfolgen würde, kommt jetzt aus dem File grgew.dat. Problem hier: es wird über Größe und Gewicht gemittelt, was Unsinn ist).
dm s1 < grgew.dat | descnimmt nur die erste Spalte von grgew.dat (dies kann man demostrieren, indem man nur dm s1 < grgew.dat eingibt); die pipe | leitet dann diesen Output weiter an das Programm desc.
dm s2 < grgew.dat | desc > gew.outnimmt diesmal die zweite Spalte (also das Gewicht), berechnet dafür die deskriptiven Statistiken und speichert das Ergebnis in der Datei gew.out.
Weitere Übungen zu desc und dm
Hausaufgabe für die nächste Stunde wird es sein, Mittelwerte für 5 Versuchsbedingungen eines Tierexperimentes zu rechnen (Hausaufgabe 3.1). Die Daten sind dabei spaltenweise angeordnet:
6 12 18 24 30 -------------- 9 10 18 14 7 7 8 16 12 9 10 17 23 17 13 12 14 24 20 16 13 18 21 19 15
Es sollte der Mittelwert für 6 Stunden Deprivation berechnet werden:
dm s1 < rats.dat | desc
Verwendung von dm für Umrechnungen:
probdist rand u 100| dm "(x1*90)+10"
Hier werden erst 100 Zufallszahlen erzeugt; sie liegen bei Verwendung von u(niform) zwischen 0 und 1; mit dem Kommando dm wird der numerische Wert in der ersten Spalte (x1) extrahiert und entsprechend transformiert, so daß die resultierenden Werte zwischen 10 und 100 liegen. Die Umrechnung muß zwischen (doppelten) Anführungszeichen stehen, damit sie als zusammengehörig erkannt wird.
Hausaufgabe: Von Hausaufgabe2 die beiden restlichen Aufgaben (5 und 6) bearbeiten.
zurück zur Hauptseite zum Seminar "Rechnergestützte Auswertung von psychologischen Experimenten"
Anmerkungen und Mitteilungen an
rainer@zwisler.de